
unidada2
2.1
ORGANIZACIÓN DEL PROCESADOR
Un procesador, incluye tanto registros visibles por el usuario como registros de control/estado. Los registros visibles por el usuario pueden ser de uso general o tener una utilidad especial, mientras que los registros de control y estado se usan para controlar el funcionamiento del procesador, un claro ejemplo es el contador de programa.
Los procesadores utilizan la segmentación de instrucciones para acelerar la ejecución. La segmentación de cauce se puede dividir en ciclo de instrucción en varias etapas separadas que operan secuencialmente, tales como la captación de instrucción, decodificación de instrucción, cálculo de direcciones de operando, ejecución de instrucción y estructura del operando resultado.
A continuación se muestra cómo se organiza un procesador, para esto se tiene que considerar los siguientes requisitos:
Captar instrucciones: el procesador lee una instrucción de memoria (registro, cache o memoria principal).
Interpretar instrucción: la instrucción se codifica para determinar qué acción es necesario.
Captar datos: la ejecución de una instrucción puede exigir leer datos de memoria o de un módulo de E/S.
Procesar datos: la ejecución e una instrucción puede exigir llevar a cabo alguna operación aritmética o lógica con los datos.
Escribir datos: los resultados de una ejecución pueden exigir escribir datos en la memoria o en el módulo de E/S.
Para hacer estas cosas, el procesador necesita almacenar instrucciones y datos temporalmente mientras una instrucción esta ejecutándose, en otras palabras el procesador necesita una pequeña memoria interna.
Figura 12.1 El procesador y el bus del sistema
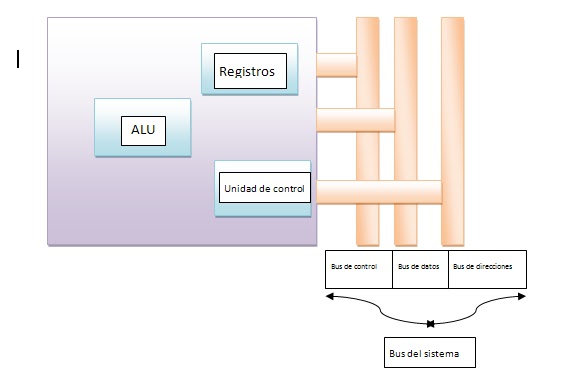
En esta figura se muestra una visión simplificada de un procesador, que indica su conexión con el resto de sistema, a través del bus del sistema. La ALU lleva a cabo el verdadero cálculo o procesamiento de datos. La unidad de control controla la transferencia de datos e instrucciones así a dentro y así afuera del procesador, y el funcionamiento de la ALU. Además la figura muestra una memoria interna mínima, que consta de un conjunto de posiciones de almacenamiento llamadas registros.
Figura 12.2 Estrucutra interna del procesador
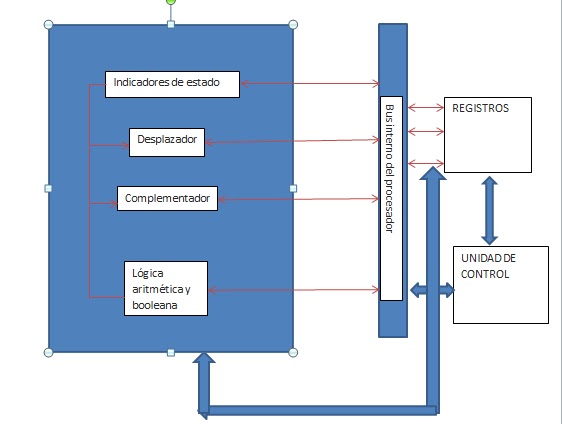
En esta figura se indican los caminos de transferencia de datos y de la lógica de control, que incluye un elemento con el rotulo bus interno del procesador. También se muestran los elementos básicos típicos de la ALU. Hay que observar la similitud entre la estructura interna del computador en su totalidad y la estructura interna del procesador. En ambos casos hay una pequeña colección de elementos principales (computador: procesador, E/S, memoria; procesador: unidad de control, ALU, registros) conectados por caminos de datos.
Conclusiòn:
En conclusión podemos decir que este tema es muy importante en nuestra carrera, ya que habla de la forma en como esta organizada un procesador, y muestra unas figuras demasiado interesantes sobre la relación bus-procesador.
El principal aporte de esta investigación es poner de manifiesto el valor que tiene el procesador en nuestra carrera de ingeniería en sistemas computacionales.
2.2
REGISTROS DEL PROCESADOR
Dentro del procesador, hay un conjunto de registros que ofrecen un nivel de memoria que es más rápido y pequeño que la memoria principal. Los registros del procesador sirven para dos funciones:
· Registros visibles de usuario: Un programador de lenguaje de máquina o ensamblador puede minimizar las referencias a memoria principal mediante un uso óptimo de estos registros. Con lenguajes de alto nivel, un compilador que optimice código intentará hacer una selección inteligente de qué variables asignar a registros y cuáles a ubicaciones de la memoria principal. Algunos lenguajes de alto nivel, como C, permiten que el programador indique al compilador qué variables se deben almacenar en registros.
· Registros de control y de estado: Son utilizados por el procesador para el control de las operaciones o por rutinas privilegiadas del sistema operativo para controlar la ejecución de los programas.
No hay una separación clara de los registros en estas dos categorías. Por ejemplo, en algunas máquinas el contador de programa es visible para los usuarios, pero en otras muchas no lo es. Sin embargo, para el propósito de la discusión que viene a continuación, es conveniente emplear estas categorías.
Registros visibles de usuario
Un registro visible de usuario es aquél que puede ser referenciado por medio del lenguaje de máquina que ejecuta el procesador y es, por lo general, accesible para todos los programas, incluyendo tanto los programas de aplicación como los del sistema. Las clases de registro que, normalmente, están disponibles, son los registros de datos, los registros de dirección y los registros de códigos de condición.
Los registros de datos
Pueden ser asignados por el programador a diversas funciones. En algunos casos, son de propósito general y pueden ser empleados por cualquier instrucción de máquina que lleve a cabo operaciones sobre los datos. Sin embargo, suelen ponerse ciertas restricciones a menudo. Por ejemplo, puede haber registros dedicados a operaciones en coma flotante.
Los registros de dirección
Contienen direcciones en la memoria principal de datos e instrucciones o una parte de la dirección que se utiliza en el cálculo de la dirección completa. Estos registros pueden ser de propósito general o pueden estar dedicados a un modo específico de direccionamiento.
Entre los ejemplos se incluyen:
· Registro índice: El direccionamiento indexado es un modo común de direccionamiento que implica sumar un índice a un valor base para obtener la dirección efectiva.
· Puntero de segmento: Con direccionamiento segmentado, la memoria se divide en segmentos, que son bloques de palabras de tamaño variable. Una referencia a memoria consta de una referencia a un segmento particular y un desplazamiento dentro del segmento. En este modo, se utiliza un registro que alberga una dirección base (ubicación inicial) de un segmento. Puede haber varios registros de este tipo: por ejemplo, uno para el sistema operativo (es decir, cuando se ejecuta código del sistema operativo en el procesador) y otro para la aplicación que está en ejecución.
· Puntero de pila: Si hay un direccionamiento de pila visible para los usuarios, la pila estará, por lo general, en la memoria principal, existiendo un registro dedicado a señalar la cima de la pila.
Esto permite el uso de instrucciones que no contienen ningún campo de dirección, tales como push (poner) y pop (sacar).
Una última categoría de registros que son, al menos, parcialmente visibles para los usuarios, son aquellos que contienen códigos de condición (también denominados indicadores o flags). Los códigos de condición son bits activados por el hardware del procesador como resultado de determinadas operaciones.
Registros de control y de estado
Varios registros se emplean para controlar las operaciones del procesador. En la mayoría de las máquinas, la mayor parte de estos registros no son visibles para los usuarios. Algunos de ellos pueden estar accesibles a las instrucciones de máquina ejecutadas en un modo de control o modo del sistema.
Por supuesto, máquinas diferentes tendrán organizaciones diferentes de registros y podrán usar terminologías distintas.
2.4
La segmentación (en inglés pipelining, literalmente tuberia o cañeria) es un método por el cual se consigue aumentar el rendimiento de algunos sistemas electrónicos digitales. Es aplicado, sobre todo, en microprocesadores. El nombre viene de que para impulsar el gas en un oleoducto a la máxima velocidad es necesario dividir el oleoducto en tramos y colocar una bomba que dé un nuevo impulse al gas. El símil con la programación existe en que los cálculos deben ser registrados o sincronizados con el reloj cada cierto tiempo para que la ruta crítica (tramo con más carga o retardo computacional entre dos registros de reloj) se reduzca.
La ruta crítica es en realidad la frecuencia máxima de trabajo alcanzada por el conjunto. A mayor ruta crítica (tiempo o retraso entre registros) menor es la frecuencia máxima de trabajo y a menor ruta crítica mayor frecuencia de trabajo. La una es la inversa de la otra. Repartir o segmentar equitativamente el cálculo hace que esa frecuencia sea la óptima a costa de más área para el almacenamiento o registro de los datos intervinientes y de un retraso o latencia (en ciclos de reloj/tiempo) en la salida del resultado equivalente al número de segmentaciones o registros realizados. La ventaja primordial de este sistema es que, tal y como se muestra en la imagen, una vez el pipe está lleno, es decir, después de una latencia de cuatro en la imagen, los resultados de cada comando vienen uno tras otro cada flanco de reloj y sin latencia extra por estar encadenados dentro del mismo pipe. Todo esto habiendo maximizado la frecuencia máxima de trabajo.

Detalle de la segmentación de instrucciones.
El alto rendimiento y la velocidad elevada de los modernos procesadores, se debe, principalmente a la conjunción de tres técnicas:
- Arquitectura Harvard (arquitectura que propicia el paralelismo).
- Procesador tipo RISC.
- La propia segmentación
La segmentación consiste en descomponer la ejecución de cada instrucción en varias etapas para poder empezar a procesar una instrucción diferente en cada una de ellas y trabajar con varias a la vez.
En el caso del procesador DLX podemos encontrar las siguientes etapas en una instrucción:
IF (Instruction Fetch): búsqueda
ID (Instruction Decode): decodificación
EX (Execution): ejecución de unidad aritmético lógica
MEM (Memory): memoria
WB (Writeback): escritura
Cada una de estas etapas de la instrucción usa en exclusiva un hardware determinado del procesador, de tal forma que la ejecución de cada una de las etapas en principio no interfiere en la ejecución del resto.
En el caso de que el procesador no pudiese ejecutar las instrucciones en etapas segmentadas, la ejecución de la siguiente instrucción sólo se podría llevar a cabo tras la finalización de la primera. En cambio en un procesador segmentado, salvo excepciones de dependencias de datos o uso de unidades funcionales, la siguiente instrucción podría iniciar su ejecución tras acabar la primera etapa de la instrucción actual.
Otro ejemplo de lo anterior, en el caso del PIC, consiste en que el procesador realice al mismo tiempo la ejecución de una instrucción y la búsqueda del código de la siguiente.
2.5
1. Introducción
En Marzo de 1999 apareció en el mercado el Pentium III, conocido en la etapa de proyecto como Katmai. Es un Pentium II mejorado, por lo que durante casi 2 años fue el microprocesador debandera de Intel, pues, a las ventajas del Pentium II Xeon, incorpora nuevas instrucciones de microcódigo que mejoran la capacidad de manejo de 3-D (instrucciones Katmai). En un inicio el Pentium III se comercializó a 500 MHz, pero actualmente su velocidad supera el 1 GHz. Como miembro de la familia de procesadores P6, generación de procesadores que le sucedió a la línea Pentium de Intel se caracteriza por la implementación de la microarquitectura de ejecución dinámica, la cual incorpora una única combinación de la predicción de salto múltiple, análisis del flujo de datos y la ejecución especulativa. Esto hizo posible que lafamilia P6 tuviera un mayor rendimiento que la familia Pentium mientras mantenía la compatibilidad binaria con la arquitectura de los procesadores anteriores de Intel.
La potencia de un procesador Intel® Pentium III, brinda desempeño y confiabilidad, que es mejor para la mayor parte de los consumidores y usuarios de negocios, a continuación las características que especifican el procesador Pentium III.
2. Características Técnicas
· Integra la arquitectura Dual Independent Bus (DIB), un bus de sistema de transacción múltiple y la tecnología de realce de medios Intel MMX
· Ofrece extensiones Streaming Single Instruction Múltiple Data (SSE) Las extensiones "Streaming SIMD" también conocidas como MMX2 o KNI, Katmai New Instructions. Se diferencia de las ultimas MMX en que las ultimas operaban con dos enteros de 32 bits, mientras que las SSE con cuatro valores de punto flotante simultáneamente. Constan de 70 nuevas instrucciones que incluyen: instrucciones únicas, datos múltiples para coma flotante, instrucciones de enteros SIMD adicionales e instrucciones para el control del almacenamiento caché. Entre las tecnologías que se benefician de las extensiones "Streaming SIMD" se incluyen las aplicaciones avanzadas de tratamiento de imágenes, sonido y vídeo, y reconocimiento de la voz. Más concretamente:
- Visualización y manipulación de imágenes de mayor resolución y calidad.
- Vídeo MPEG2 y sonido de alta calidad, y codificación y decodificación MPEG2 simultáneas.
- Gran parte de los procesadores Intel Pentium III vienen equipados con una cache de transferencia avanzada, y un avanzado sistema de almacenaje intermediario para alcanzar los requisitos de datos que requieren gran ancho de banda en los ambientes de hoy (tratamiento de imagen, CAD, WindowsNT).
· Incorpora la cache primaria o Level 1(L1) de 32K (16K para instrucciones y 16K para los datos) para ofrecer las más altas velocidades de acceso a la información disponible. La cache de no-bloqueo L1, le brinda un acceso rápido a los datos utilizados más frecuentemente.
· Existen versiones que incorporan segundo nivel de cache L2 de 256 KB de Cache de Transferencia avanzada integrada a toda velocidad concódigo de corrección de errores (ECC) o versiones que incorporan una cache L2 discreta de 512 KB a media velocidad con ECC en el paquete que mejora las maniobras de la protección y la capacidad del receptáculo
· Existen versiones del procesador Intel Pentium III con bus de sistema de 100 MHz ó 133 MHz donde el procesador esta disponible a la misma frecuencia especifica del núcleo aparte de los 100 MHz y 133 MHz de las versiones del Front Side Bus
· Basado en la micro arquitectura Intel P6, y con tecnología Intel SpeedStep Intel P6, es una nueva tecnología revolucionaria que le permite cambiar automáticamente los modos del desempeño máximo para optimizar la vida de la batería.
· La Tecnología Intel QuickStart para procesadores móviles optimiza el consumo de energía mediante el trabajo a un grado de potencia general más bajo cuando el sistema está inactivo.
· El uso de la tecnología de Intel de 0.18-micrones disminuye el tamaño del procesador para un desempeño y movilidad sin precedentes ya que antes era solo hasta 0.25 micrones y que permite incorporar 28 millones de transistores en solo 105 mm cuadrados.
· Se encuentra disponible en las velocidades de hasta 1.33GHz. utilizando la tecnología de 0.13 micrones.
Arquitectura de ejecución dinámica en Pentium III
El mecanismo de ejecución fuera de orden llamado "Ejecución Dinámica incorpora tres conceptos importantes:
· Predicción de saltos profunda. Permite decodificar instrucciones más allá de las ramificaciones para mantener el pipeline lleno. Algoritmo de predicción optimizado. Predice el flujo del programa a través de varias ramificaciones: mediante un algoritmo de predicción de ramificaciones múltiples, el procesador puede anticipar los saltos en el flujo de las instrucciones. Éste predice dónde pueden encontrarse las siguientes instrucciones en la memoria con una increíble precisión del 90% o mayor. Esto es posible porque mientras el procesador está buscando y trayendo instrucciones, también busca las instrucciones que están más adelante en el programa. Esta técnica acelera el flujo de trabajo enviado al procesador.
· Análisis dinámico del flujo de datos. Análisis en tiempo real para detectar la posibilidad de ejecución fuera de orden, optimizando el uso de las unidades de ejecución. Analiza y ordena las instrucciones a ejecutar en una sucesión óptima, independiente del orden original en el programa: mediante el análisis del flujo de datos, el procesador observa las instrucciones de software decodificadas y decide si están listas para ser procesadas o si dependen de otras instrucciones. Entonces el procesador determina la sucesión óptima para el procesamiento y ejecuta las instrucciones en la forma más eficiente.
· Ejecución Especulativa. Habilidad de ejecutar instrucciones por delante del contador de programa. Utiliza el análisis anterior y va ejecutando todas las instrucciones posibles. Aumenta la velocidad de ejecución observando adelante del contador del programa y ejecutando las instrucciones que posiblemente van a necesitarse. Cuando el procesador ejecuta las instrucciones (hasta cinco a la vez), lo hace mediante la "ejecución especulativa. Como las instrucciones del software que se procesan con base en predicción de ramificaciones, los resultados se guardan como "resultados especulativos". Una vez que su estado final puede determinarse, las instrucciones se regresan a su orden propio y formalmente se les asigna un estado de máquina.
Puede afirmarse que la ejecución dinámica elimina las limitaciones del empleo de una secuencia lineal de instrucciones entre las fases de búsqueda y ejecución tradicionales. Esta permite decodificar instrucciones que se encuentren en múltiples niveles de ramificaciones para mantener el pipeline de instrucciones lleno. También permite la ejecución de instrucciones fuera de orden para mantener las unidades de ejecución de instrucciones del procesador corriendo a toda capacidad. Finalmente entrega los resultados de las instrucciones ejecutadas en el orden original del programa para mantener la integridad de los datos y la coherencia del programa sobresaliente de ejecución fuera de orden, optimizando el uso de las unidades de ejecución, todo esto se logra con la implementacion por hardware de la arquitectura que garantice la Ejecución Dinámica y a la cual hacemos referencia seguidamente.
La microarquitectura de un superpipeline con características multietapas, el cual trata de trabajar menos por etapa de pipeline para un numero de 20 etapas 33 % menos que en el procesador Pentium, lo que ayuda a lograr un mayor rango del reloj en el proceso. Esta microarquitectura elimina la secuencia tradicional entre las fases de búsqueda y ejecución y amplia el ancho de la ventana de instrucciones con la utilización de la piscina de instrucciones. Esto le permite al procesador tener mucho mas visibilidad dentro del flujo de instrucciones del programa en la fase de ejecución lo que mejora la planificación. Esto necesita de una mayor eficiencia del procesador en la fase de búsqueda y decodificación en términos de la predicción del flujo del programa. Una planificación optimizada necesita la fase de ejecución que es reemplazada por fase doble "despacho /ejecución" y la fase de "retiro". Esto permite que las instrucciones sean comenzadas en cualquier orden pero que siempre sean completadas en el orden original del programa, por lo que se puede considerar tres mecanismos acoplados con una piscina de instrucciones como se muestra en la figura.
· La Unidad de Búsqueda/Decodificación: Es una unidad que toma como entrada el flujo de instrucciones del programa del usuario en orden de la
· Cache de instrucciones y las decodifica en una serie de µoperaciones que representan el flujo de datos. La pre-busqueda es especulativa.
· La Unidad de Despacho/Ejecución: Es una unidad fuera de orden que acepta el flujo de datos, planifica la ejecución de las µops sujetas a la dependencia de datos y a la disponibilidad de recursos y almacena temporalmente los resultados de las ejecuciones especulativas.
· La Unidad de Retiro: Es una unidad fuera de orden que conoce como y cuándo retirar los resultados temporales especulativos al estado arquitectural permanente.
· La Unidad de Interfaz con el Bus: Es la unidad parcialmente ordenada responsable de la conexión con el mundo real de las tres unidades internas.
· Comunica directamente con el segundo nivel de cache L2 soportando hasta cuatro accesos de cache concurrentemente. Esta unidad también controla las transacciones del bus con el protocolo MESI y con el sistema de memoria.

A continuación una muestra detallada de cada una de las unidades que garantizan la ejecución dinámica.
Arquitectura multinucleo
HISTORIA
Como historia se puede decir que el primer procesador multinúcleo en el mercado fue el IBM Power 4 en el año 2000. Una alternativa a los procesadores multinúcleo son los sistemas multiprocesadores, que consisten en una placa madre que podía soportar desde 2 a más procesadores. El rendimiento es bastante bueno, pero también es bastante caro.
DESCRIPCION
Un microprocesador multinúcleo es aquel que combina dos o más procesadores independientes en un sólo circuito integrado. Un dispositivo doble núcleo contiene solamente dos microprocesadores independientes. En general, los microprocesadores multinúcleo permiten que una computadora trabaje con Multiprocesamiento, es decir procesamiento en simultáneo con dos o más procesadores. Por otro lado, la tecnología de doble núcleo mejora el rendimiento de los entornos de trabajo multitarea y las aplicaciones con múltiples subprocesos. Por ejemplo, permite que aplicaciones fundamentales como antivirus o antiespías se ejecuten al mismo tiempo que aplicaciones empresariales con un impacto mínimo sobre el rendimiento del sistema.
Durante agosto de 2007 comenzaron a aparecer los procesadores de cuádruple núcleo, encabezados por el lanzamiento del Core 2 Quad de Intel. En el caso de las computadoras portátiles.
CLASES DE PROCESADORES MULTINUCLEOS
Antes de comenzar a nombrar los diferentes procesadores multinucleo definieremos lo que es HyperThreading.
HyperThreading: esta tecnología fue creada por Intel, para los procesadores Pentium 4 más avanzados. El Hyperthreading hace que el procesador funcione como si fuera dos procesadores. Esto fue hecho para que tenga la posibilidad de trabajar de forma multihilo (multithread) real, es decir pueda ejecutar muchos hilos simultáneamente.
Un procesador con la tecnología Hyperthreading tiene un 5% más de transistores que el mismo procesador sin esa tecnología.
Clases de procesadores multinucleo INTEL:
PentiPentium D están conformados por dos procesadores Pentium 4 Prescott sin Hyperthreadingum.
Core Duo
Core 2 Duo
Core2Quad
Clases de procesadores multinucleo AMD:
Athlon 64 X2
Opteron X2
Turion X2 (Portatiles)
FUTURO DE LOS PROCESADORES MULTINÚCLEO